
Comparative Judgement (CJ) has transformed the way we assess writing at Paradigm Trust – we use it from key stage 1 to key stage 4 in English, RE, science, history and geography. It lets us compare performance across our schools meaningfully and provides us with national data to standardise our data.
When I download the data, usually I head straight for the score, but there is much more in the spreadsheet. This post explains two additional values which can help inform decisions as a teacher and a school leader: standard error (SE) and infit.

Standard Error
One of the great unsung advantages of using NoMoreMarking is that it provides the standard error for each pupil’s score. When we know how far we can trust each score, we don’t make bigger inferences than the data supports.
Standard error comes about because an assessment can’t measure a person’s true ability precisely. Any assessment gets it wrong at least a bit. The trick is knowing how much.
This chart represents the standard error information from NoMoreMarking for a recent RE writing task for year 4:
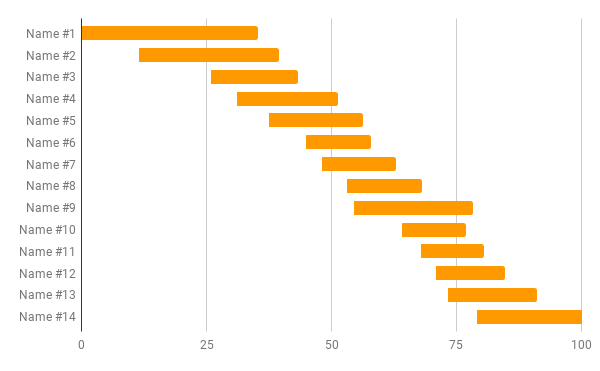
Person #1 has the lowest score, but also the biggest standard error. This pupil’s ‘true’ RE writing ability score will be somewhere between 0 and 35. Well, probably. Each person’s ‘true’ score is only 67% likely to be within their bar. One sixth of the time, the learner will be really be higher and one sixth of the time, lower. In a standard class of 30, around ten learners are likely to be outside of the assessment’s standard error.
Another way of representing standard error is with a dot-plot.
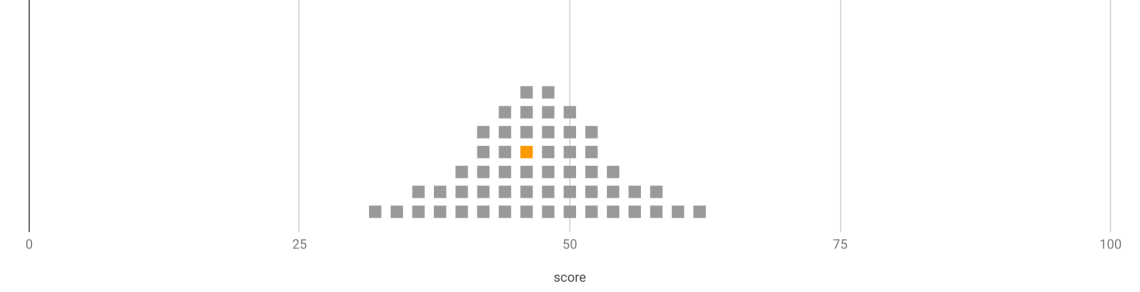
Each grey square represents another assessment task the learner could have completed – the orange one represents the task actually written. The ‘true’ ability of the learner is likely to be within this range.
Surely this is a scandal? Can’t we do better? Well, maybe, but only if we spend much more time assessing (this is why GCSE exams are so long). Precision in assessment means sampling the domain more thoroughly – by asking more questions and by setting more tasks. In the real world we have to learn to live with a larger standard error than we would like. As long as we understand this, we can make better decisions about setting and interventions and judge how confident we can be about the progress.
Infit (Quirkiness)
NoMoreMarking provides another useful variable – infit.
The mathematical algorithm behind NoMoreMarking assumes that there is a smooth progression from the worst script to the best. It assumes the worst script has the worst handwriting, the worst grammar and vocabulary and the least interesting story, while the best has the best of each variable. Some scripts might fall on that nice, straightforward progression, but many do not. The algorithm then measures how far off the actual piece of writing is.
Infit is a measure of how ‘quirky’ the each individual’s writing is. A high infit score tells you that there was something unusual about the writing – perhaps the vocabulary was wonderful, but there were no paragraphs, or the writing was thoughtful and interesting, but the grammar was shocking.
A low infit score tells you that the script was pretty much as you’d expect for a pupil performing at that level – the spelling, vocabulary, grammar and content are well aligned.
By plotting the infit as the x-axis and the score on the y-axis, you can clearly see which texts were unusual.
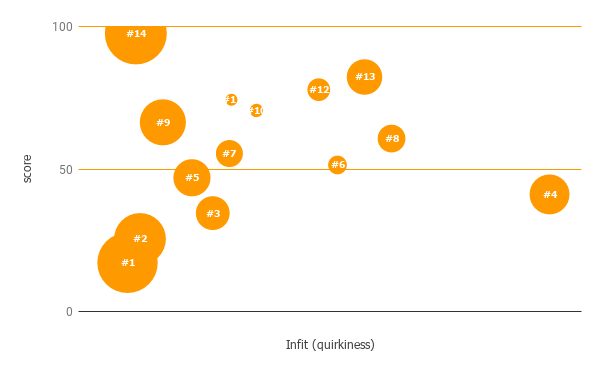
Person #4 obviously stands out, but #6, #8, #12 and #13 also seem quirky. It would be worth looking closely at those scripts.
The other scripts are more or less on a predictable path. You can be confident that the scripts by #1 and #2 will benefit from the same feedback, as will #3, #5 and #7.
At Paradigm Trust we have started to use standard error and infit to understand our assessment data. We’ve done a lot of thinking and a lot of training. In my next few posts, I will be sharing how we report to parents and how we assess the quality of our multiple choice assessments.
(You may also notice how much fun I’m having learning about data visualisation).
Ben

Hi Ben,
We are currently using CJ in Primary, but not in secondary. I feel as a small school that the judgements will be very high for the 3 English teachers or the 2 History teachers. Is there a way around this or is it just down to numbers of staff?
Very interested in your analysis above, where did you get the information from each script after the judging window?
Thanks for showing what you do!
Darren
LikeLike
Hi Darren – thanks for getting in touch. I don’t think there’s a way around the number of judgements – you need about 10 judgements per script, so for a class of 30 you need 300 comparisons in total. The more colleagues you can share this out among, the lighter the load. It’s still worth bearing in mind the alternative or rubric marking is likely to take significantly longer. But an hour of CJ starts to feel like torture.
The info is on the download csv file. I usually open in google sheets. The headings are all there.
Happy to keep talking.
Ben
LikeLike